Modeling and Benchmarking Spoken Dialogue Rewards with Modality and Colloquialness
Abstract
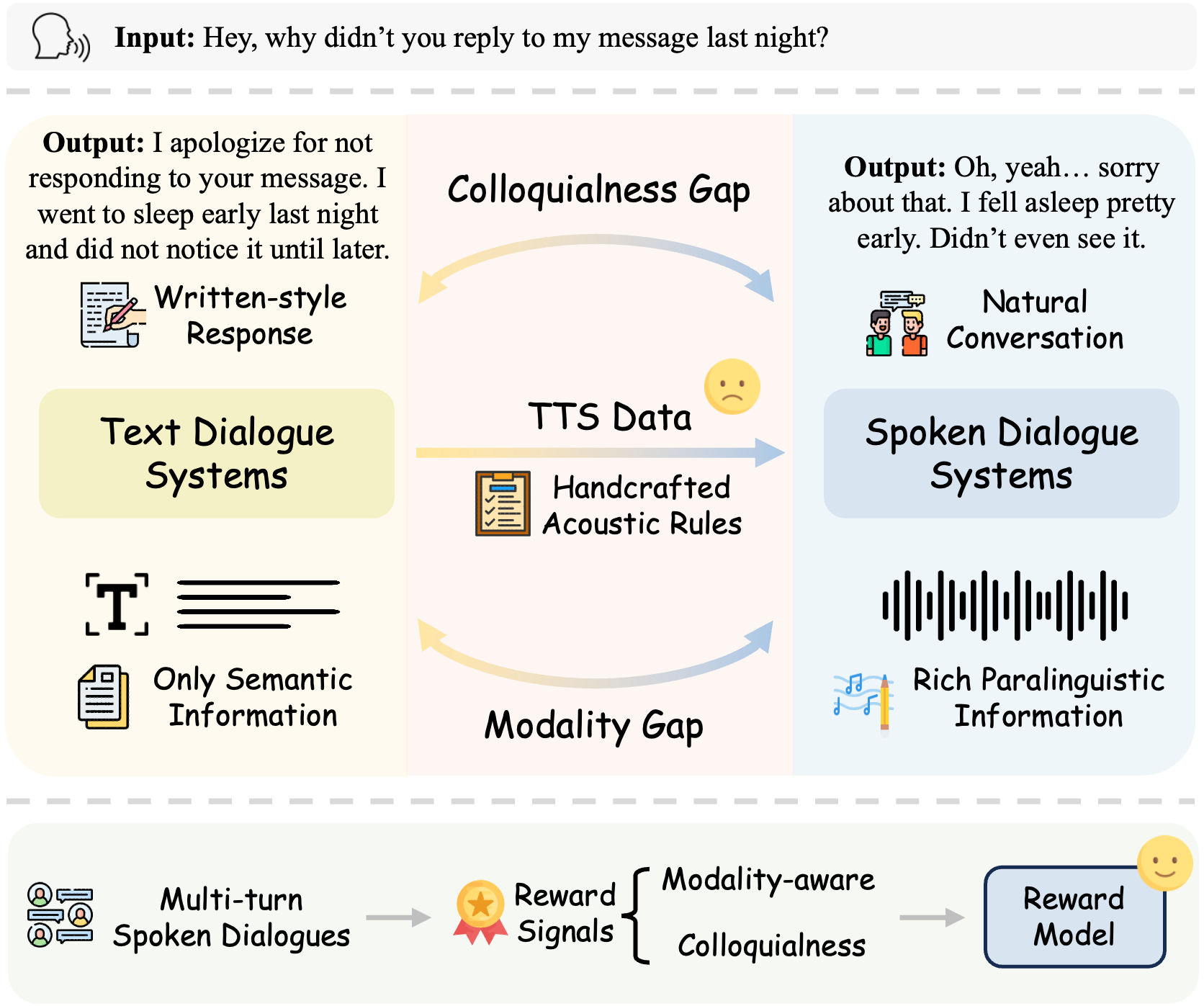
The rapid evolution of end-to-end spoken dialogue systems demands transcending mere textual semantics to incorporate paralinguistic nuances and the spontaneous nature of human conversation. However, current methods struggle with two critical gaps: the modality gap, involving prosody and emotion, and the colloquialness gap, distinguishing written scripts from natural speech.
To address these challenges, we introduce SDiaReward, an end-to-end multi-turn reward model trained on SDiaReward-Dataset, a novel collection of episode-level preference pairs explicitly targeting these gaps. It operates directly on full multi-turn speech episodes and is optimized with pairwise preference supervision, enabling joint assessment of modality and colloquialness in a single evaluator. We further establish ESDR-Bench, a stratified benchmark for robust episode-level evaluation. Experiments demonstrate that SDiaReward achieves state-of-the-art pairwise preference accuracy, significantly outperforming general-purpose audio LLMs. Further analysis suggests that SDiaReward captures relative conversational expressiveness beyond superficial synthesis cues, improving generalization across domains and recording conditions.